Process
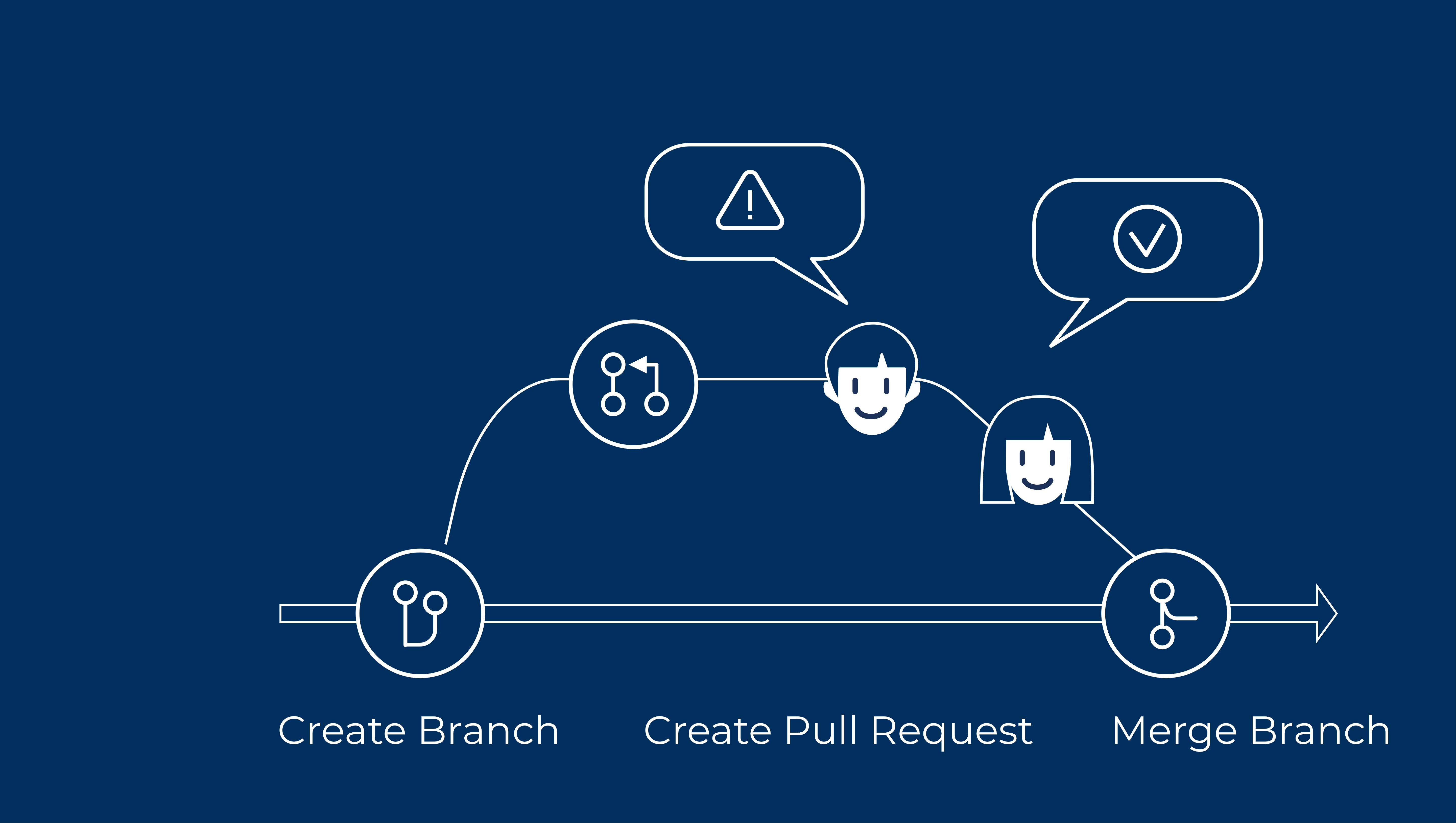
Technical Quality Control
[ Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live ]
— John F. Woods. We are against violence, but we agree with the approach.
Testing and architecture control for early-stage products is much different from the way it works for mature products. There are many hypotheses, the entrepreneur's understanding of the market changes frequently, and requirements change unpredictably. At the same time, the product's core features must work consistently and be ready for future increments.
Therefore, we cannot have a clear and realistic roadmap six months ahead. Maybe, if the product has a stable plan for several months, then a separate testing process performed by the QA team is reasonable. But in our cases, it is much more effective if developers test the product by themselves. Only they know and understand the current requirements and have the conditions to check the product appropriately.
We analyze the correctness and predictability of the increment, considering extreme cases. We make sure that the system remains operable for any incorrect input data. If the requirements contain performance constraints, we check them thoroughly. Wherever there is a minimum need, we ensure that we can increase the limits by an order of magnitude. Therefore, we have a clear vision of improving the limitations and how it affects stability for each part of the product.
The maintainability of the code base is extremely important, so every increment is reviewed by another developer. We look at the codebase in terms of different scenarios of interaction with it: planning an increment, developing features, bug fixing. We decide how much energy and time it is worth spending on analyzing the technical quality of the solution, depending on how long the solution remains in the product. But if each day of delay in releasing a feature causes a significant profit loss for our client, we certainly won't argue which design pattern is better. Our code reviews are flexible, non-blocking, and efficient with this approach.
We strive to keep our development process and technical discussions as productive as possible. That's why we use static analyzers, editorconfig, and other tools in this area. Such tools help us make code-style decisions, and we can focus on the important stuff.
For mature modules and applications, we develop and maintain automatic tests. With their help, we create high-quality documentation and reduce the human factor. Automated testing is not just a tool to check the execution of constraints on a subsystem. At the same time, the test represents an exact fact written by the developer: the result of the code must be exactly that. Besides, there are cases when it is faster to develop some module by writing tests for it beforehand. Also, they explain the developer's thoughts and understanding of the task, which is very valuable for the release manager and future team members. But in unstable systems, the requirements become outdated very quickly. So for MVP and temporary solutions, we often abandon automatic tests in favor of development speed.
Using all these approaches, we keep the technical quality of our products high and the prices of our services reasonable.

Product Quality Control
Our clients value us for high-quality standards. It's not just about code cleanliness, formal compliance with requirements, or 100% test coverage. We do our best for the end-user and our client's benefit.
Let's get to the specifics and look at the task block. Before the release, you need to ensure that it solves the business objectives. Then we agreed on specific goals and properly documented them during the "Collect Requirements" stage. During the "Requirements Development" stage, we described clear acceptance criteria. At the "System Testing" stage, we ensured that the increment was stable and did not threaten the system. The job is almost done, and we just need a successful release in production, right? Let's break it down.
First, we make sure that all the inputs are up-to-date. Here's how we do this:
- The client is responsible for keeping us informed about changes in their processes, so we always work with up-to-date inputs. Sometimes it may not be so apparent to the client that some changes in their process affect the product. Our task is to draw the client's attention to such moments and clarify them.
- We constantly monitor a set of basic product metrics for mature products. If there is any problem, we check with the client to see if something has changed on their end. We constantly process bug reports to know the real problems of the product. This way, we can accurately plan new increments, taking into account existing complexities and giving the most accurate estimates possible.
- Next, we make sure that the increment quality check plan is up-to-date, and we move on to its execution. Here we work with the user's goals, expectations, and behavior. At first contact, the user may not fully understand the purpose of the product. Therefore, the interface should tell the user how to use the product. Users may be different in their professional level, cultures, and level of technical literacy. Therefore, we must adapt interfaces to the target audience, which is worth testing in practice. Finally, the user may take unpredictable and even harmful actions. The product must effectively prompt the user with the proper interaction scenario and warn them against incorrect actions.
Once we are confident that an incremental product is good enough for today, we evaluate its readiness for future threats. We assess the growth of product risks based on our clients' financial interests. We prepare a risk assessment for the client and decide whether we accept these risks or change our action plan.
We can and should calculate the level of achievement of product goals. Without this, any assessment of product quality will be subjective. For the obtained product metrics to be effective, the following conditions must be met:
- Any metric requires a representative sample of users on which the metric makes sense. The simplest example, there is no point in evaluating the conversion rate of a landing page unless there is an opportunity to attract an audience interested in the product.
- Metrics should be practical; it should be clear what to do about them. For instance, 40% of users reach the third screen on the landing page. Then what? How will this fact help increase sales?
- The technical implementation must be of high quality. Imagine a situation where you buy traffic to a landing page, and the developer implements the Google Analytics integration in such a way that it doesn't work on mobile phones. As a result, the budget is wasted.
We do not have such mistakes. Some of product metrics could be collected programmatically and we do this by using 3rd-party (like Google Analytics or AppsFlyer) or by custom developments. In some cases it's too labor-intensive and it is more profitable to calculate the values of the metric manually at the right time. We always choose optimal way for better collecting metrics. It's important to mark, that you can trust to our product metrics.
We know how difficult it is to make a quality product, not just code. If we enter into a partnership, we take responsibility for the final level of the product. This work is the essence of our company, and we do it professionally.

Product release
We are proud of the frequency and seamlessness of our releases. This is true for both a minor quick fix and a significant product feature. When the increment is clear to the product owner and well assessed by our team, we can release it quickly and painlessly. Only in rare cases when a release could threaten the product's stability, we warn the client about it and freeze endangered functionality for release time.
Of course, with any release, the most important thing is not to damage the system's current state. That's why we always have a plan for returning the product to the previous state without losses. We test this plan in a safe environment equivalent to production for complex cases. But usually, the default process covers the vast majority of release scenarios.
The release usually does not take a significant amount of time. We always make a continuous delivery pipeline at the beginning of a project. It gives us the ability to release a new version of the application with one click. Our releases are almost always invisible for users, as well. For a web app release, the user may think that the Internet is down for a few seconds. But what if, at that moment, a user was paying for some services? No problem, we carefully work through such situations and never charge a user twice.
But sometimes, the task is more complicated. For example, we add a new resource-intensive search with many parameters over a large number of records. That may require you to change the data schema, build indexes in the database, and so on. These things take time. While our deployment scripts are making the changes, the users cannot access some of the data. That is precisely where an alternative solution could do well. We assess the risks of the system, consider the interests of our client and the end-users, and then choose the best solution. If a short-term shutdown would be the best solution, we will notify users about the planned technical maintenance. If this option is unacceptable, we have quite a few tricks to arrange a seamless release under such conditions.
Linus's law is the assertion that "given enough eyeballs, all bugs are shallow." We often confirm this observation in practice during releases. That is why usually we make releases with at least two employees. In a force majeure situation, we have a much better chance of quickly finding and fixing the problem.
After a successful release, we check the system's state for any degradation. We automate much of this work. Auto-tests ensure that the functionality they cover is working correctly. Monitoring services inspect that our infrastructure and product metrics are acceptable. Sentry shows errors in our codebase. To be completely confident that the new state is error-free, we check the product status manually. Once we are sure of the release results, we document these results in detailed release notes.
The release of a new version is always a pleasant moment. Each successful release strengthens our mutual trust with the client and helps us move forward. The appreciation of our clients, who now use a more efficient product, motivates us.
Feedback collection and analysis
How do we know we're doing it right? Feedback is the only way to know for sure. By collecting feedback, we match the development goals with the actual result. Based on the feedback, we assess how ready the product is for the opportunities and threats. For example, product threats are adequately evaluated, new features have not become more difficult to develop and estimate, and product owners see the process as successful.
The easiest way to gather feedback is through face-to-face interviews with the product's end-users. We create conditions for the feedback to be trustworthy. We offer meetings in advance so that the respondent has enough time to prepare. In the process, we clarify and document all important details.
But this is just the tip of the iceberg. No matter how motivated respondents may be in providing feedback, we cannot form the full picture in this way due to the following reasons:
- The level of competence of the respondent may often be insufficient for a reliable answer to the question. For example, a user of a CRM system will not give a constructive evaluation of the interface's efficiency. He may not even suggest that it could be improved.
- Sometimes subjective factors distort the feedback so much that we cannot consider it reliable. If we hear from a respondent something like, "good, pretty-pretty good," we definitely shouldn't believe that "good"
- The sample of respondents is often skewed.
There are other ways to give feedback. Respondents provide it through their actions without realizing it. For example:
- The quantitative metrics of feature usage. If users use functionality less frequently than expected — this is a sure sign of a problem. If the average interface interaction time is higher than expected, we probably missed something.
- Unexpected technical errors during user interaction with interfaces. We track them with Sentry, sometimes with Prometheus-based monitoring with alerts, sometimes with ELK. We analyze these errors and determine whether they lead to problems.
- User bugfix requests. All is good if users use the new functionality and don't complain about it. By the number of actual bugs and the result of fixing them, you can conclude the quality of the release.
We do retrospective analysis as we gather feedback. We evaluate each potential problem based on its threat to the product. We report all our concerns about the problems to our customers, giving the full context of the situation and all necessary details.
If we hear from a customer about a significant problem, we investigate it extremely quickly and thoroughly because usually, it is the most important thing for the product to fix. Once the problem is solved, we analyze the situation, document the errors that occurred, and find ways to prevent them in the future.
We are not afraid of critical feedback; we value it highly. Where there is smoke, there is fire, so we are always open to discussing hypothetical issues. We are proactive because it's often easier to nip the problem in the bud and protect everyone from the consequences. Feedback makes us more professional because we know how to work with it even if it's tough.
Each element of the development process illustration is a link to an article. Click on it to learn more.
