Case
AllPrices
Price aggregator
- Service type:
- Agile development
- Product type:
- Price aggregator
Case

E-commerce is a large niche of IT products that was one of the first to appear, so competition among the products in this industry is pretty high. In this case, we not only built a great product in this domain and solved its most difficult technical problem but also learned all of the difficulties of product development in a highly competitive market. This cooperation resulted in a price aggregator that works with online stores using the CPA model. AllPrices collected goods from the many online stores and showed them to users by search queries. We managed to build the product, which analyzed a vast quantity of goods and helped its users to find the best proposals.

During finding an effective business model, we conducted several significant product pivots while maintaining its effectiveness. We solved for our client all development tasks in two essential stages of the project: during the Pre-Seed stage when we launched the product in the fashion industry, and during the Seed stage, when the product had to cover all product categories. As the result of the Pre-Seed stage, we built the product and successfully received a seed investment. With this money, the product started competing with companies bigger than our client by capitalization. Our client deeply learned a direction, and we solved all technological tasks while checking up on the business model. The product was started in 2016, but it was officially closed in 2021, and our client gave us all the special rights to publish the working process in detail. That's why this case contains a lot of information rarely illuminated publicly.
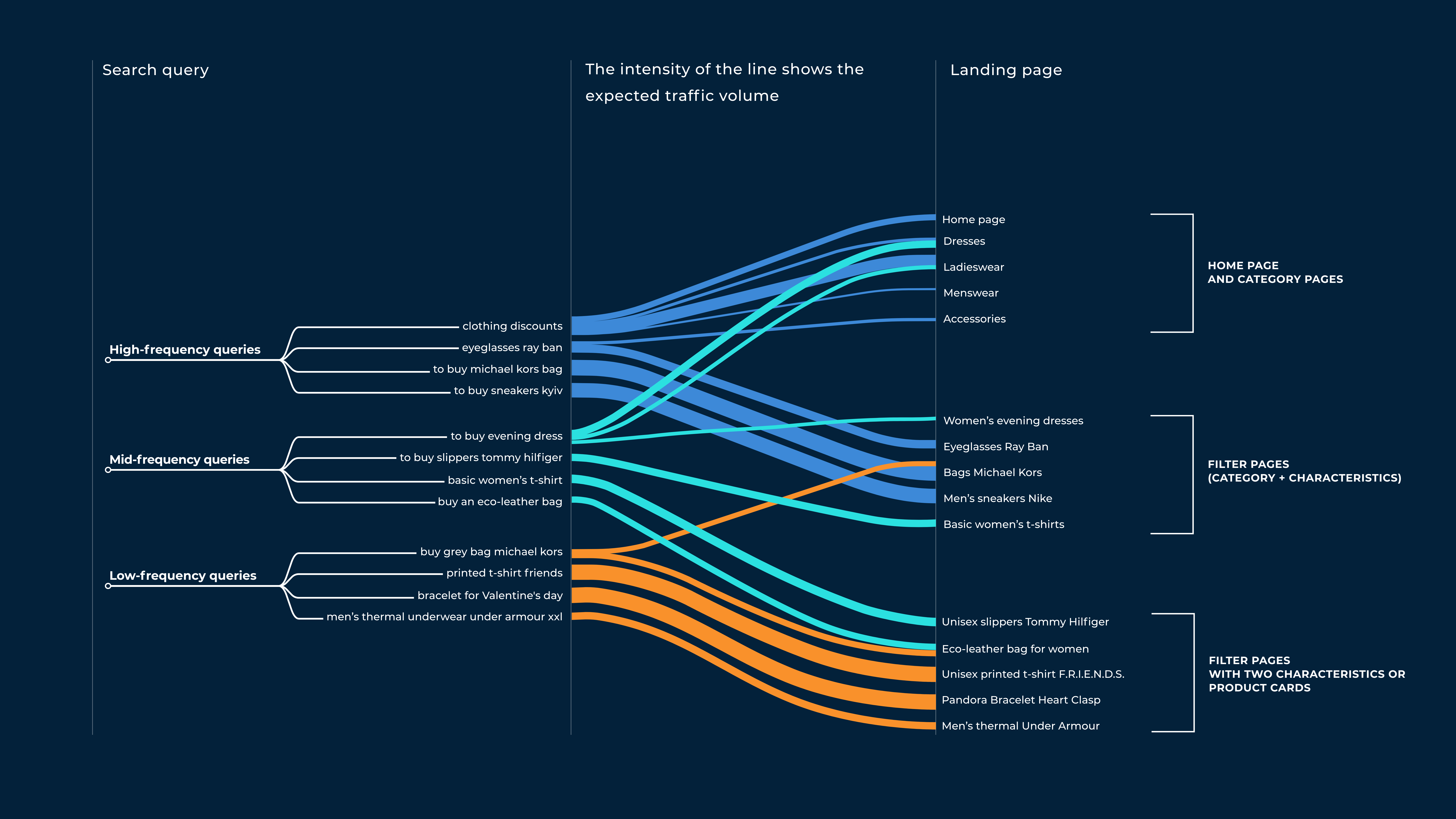
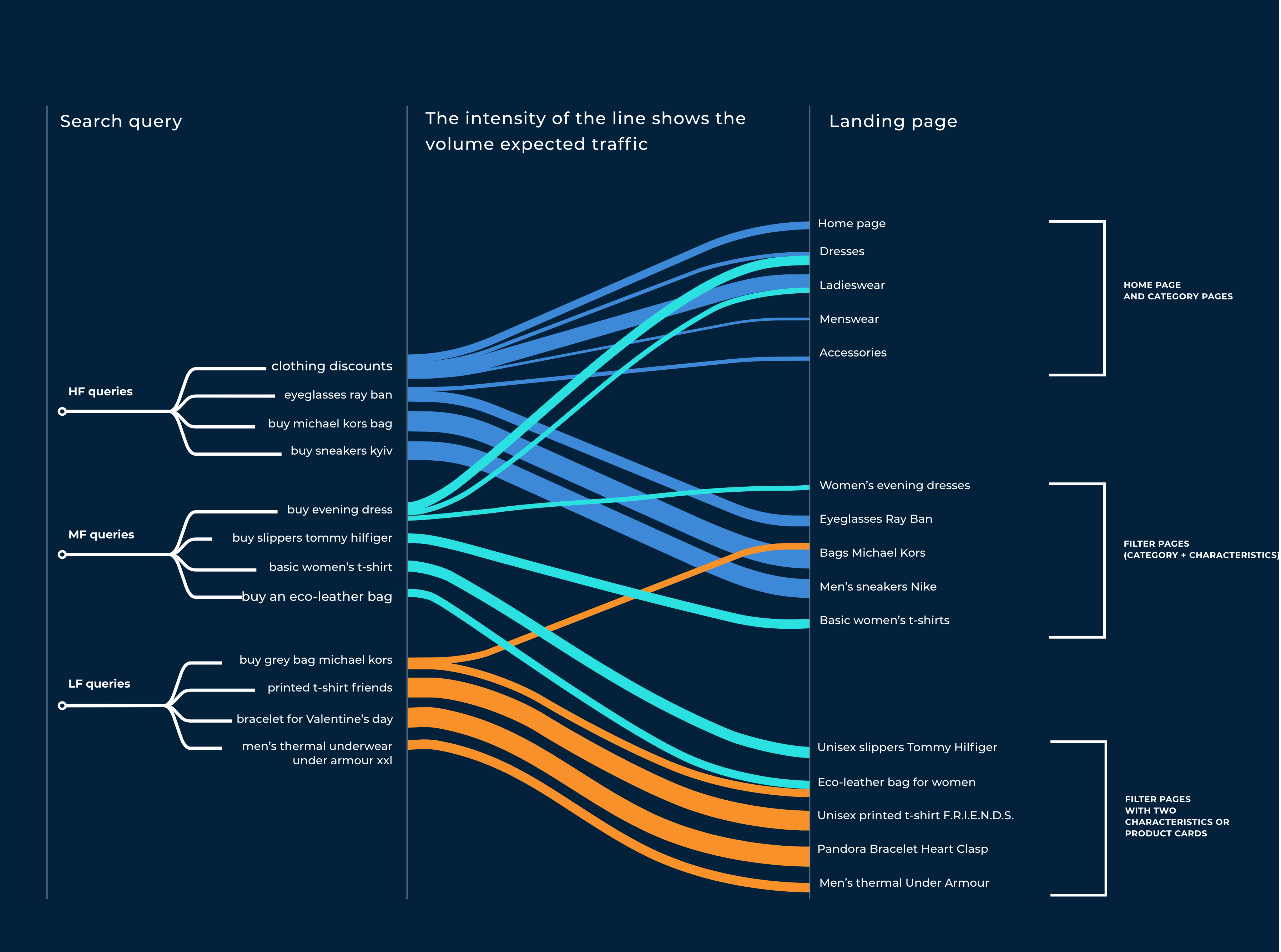
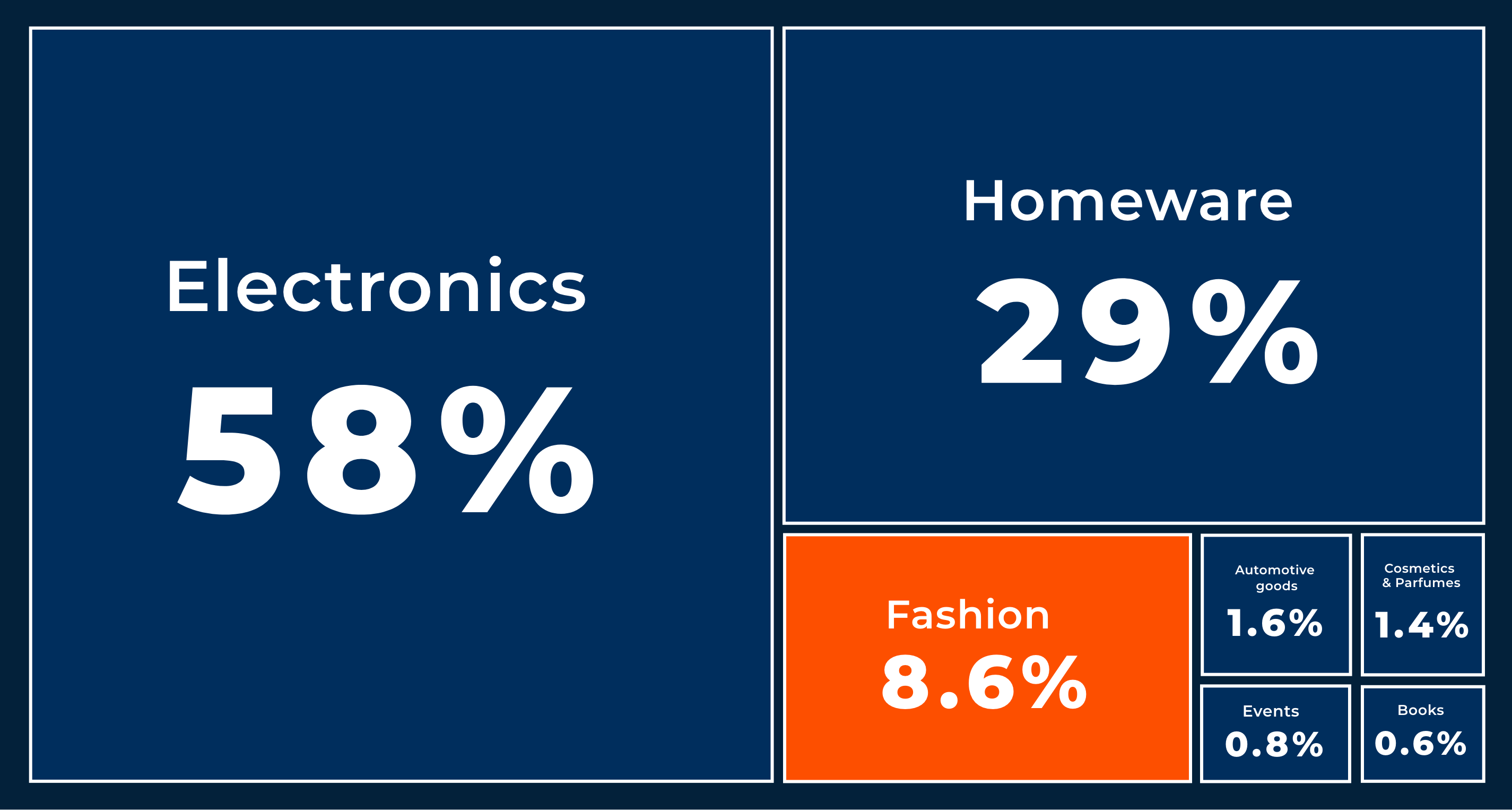
In 2016 e-commerce market in the fashion industry in Eastern Europe was differentiated: there were a lot of sellers who sold quite different products. The idea of the first version of AllPrices was simple: we needed to collect all the products of the fashion industry on one site, build a user-friendly structure of categories and filters and display real discounts for all products. At this stage, the main traffic channel was organic, and a significant role was given to the low-frequency queries. Our client saw an opportunity to massively prepare pages with relevant products for such queries and thus get substantial traffic.
Low-frequency queries are search queries that get little traffic, up to 1000 or even up to 100 visits per month. Many websites do not pay enough attention to promotion for such requests because high-quality development of these pages is often too expensive.
At that point, we decided that such an idea could work great in the fashion industry with many products. People could usually search by exact query — for example, sneakers brand, the scarf color, or text on the t-shirt. On the first page of the search, they see pages of individual stores that do not contain all the necessary products, which are not always relevant to the query. That's why our future page with goods from all online stores for this exact request was an excellent example for the visitor — it could bring the user to the desired purchase with a high possibility.
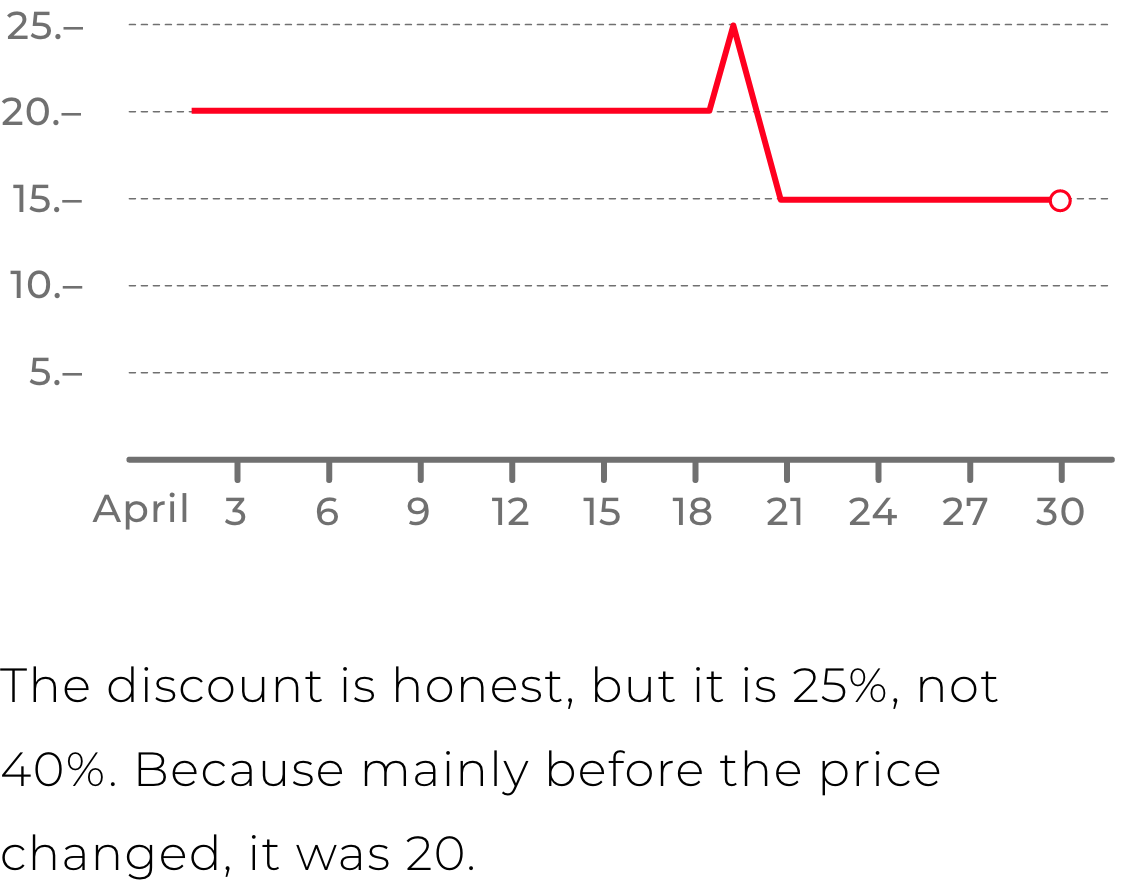
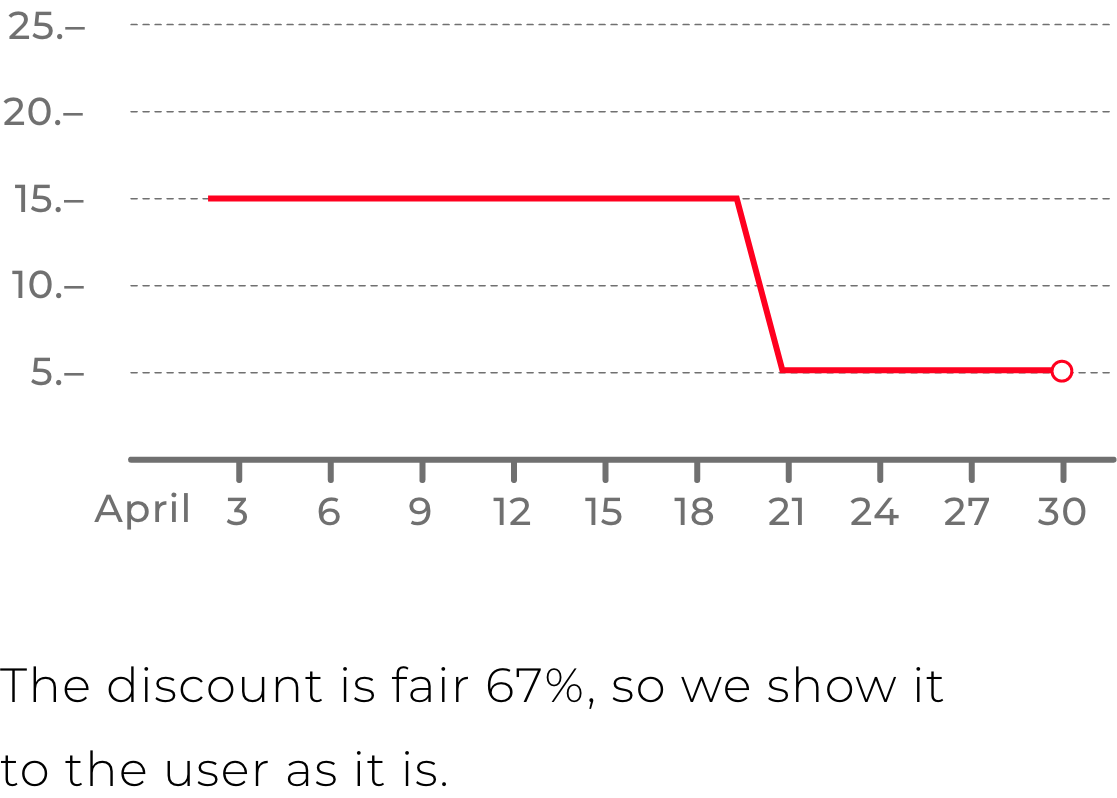
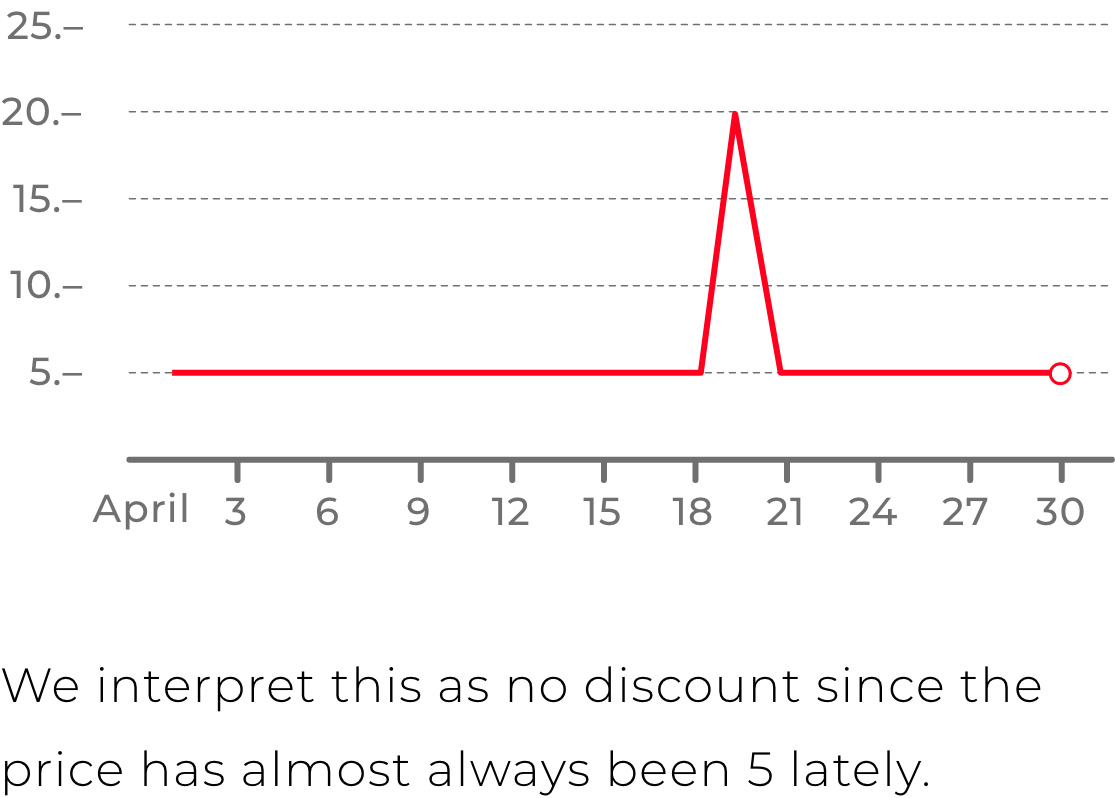
In addition to the convenience of searching among all the stores within the direction, the product had to offer the user fair discounts. We were watching product prices every day, so we could truly evaluate how the current price differs from the usual. And this discount would be honest, in a difference with many stores, which could simply put a discount badge on the product, when the price was same for the previous 30 days.

The goals we formulated with our client were more about technology than the product itself. The main task at this stage was to prove that such an IT product could be built during the Pre-Seed stage. The goals were:
For our client, the stack of the development was a principal question. Our client had an experience in the product development from his job in Cuponation (one of the significant players in this market), where he tightly cooperate with developers. The specialists who consulted them recommended the next stack:
Yii2 – famous in the Eastern Europe PHP-framework for web developers at that time.
PostgreSQL – one of the two the most popular open-source RDBMS.
Memcached – the PHP library for caching page's data.
Redis – for caching data of intermediate calculations.
We deeply learned the task and noticed several product risks, that's why we proposed a more suitable stack. Yii2 was a perfect solution for us cause that time, that framework was the most suitable for agile development, which we'd already known. Also, PostgreSQL was a solid choice for open-source RDBMS. We decided that Memcached and Redis were not fundamentally essential technologies of the product, although they could be used when necessary.
We noticed significant computational complexity of computing goods categories and properties. That's why we proposed to develop a special solution in C++, which accepts collected data from sources as input, and uploads data on categories and properties directly to the database. Also, we needed to collect data from more than 1M pages to enrich the data set. We suggested a dedicated service in Python to collect this data and import it into our DB. The client endorsed our ideas.
A hard task was product characterization process development. We aimed at defining 100K+ characteristics for 1M+ products, so manual development was out of the question. We developed a system that allowed the system to determine whether an item had each characteristic. We had raw product data from XML dumps and data from HTML pages as inputs. Simply put, these were "Description", "Material", "Size", and other fields with numeric or string values. We developed a primitive expression language, which defined the criteria if a product has some characteristic. We named such expressions normalization rules. They looked something like this:
((Name with prefix “плат”) OR (Description with prefix “плаття”)) AND
NOT ((Name with prefix “пляжн”) OR (Description with prefix “пляжн”))
Sometimes сарафани names “пляжними платтями”. They have to be in the category “сарафани”, that's why the name has prefix плат and prefix пляжн — this is сарафан, not плаття. We could generate such expressions automatically for most characteristics. Also, the content managers manually elaborated these expressions for all categories and the most popular characteristics.
The next significant task was developing the admin panel to manage the structure of all the site's pages. The category tree was a fairly typical task for this case. At the same time, creating quality filter pages looked like a task about which there's no information in a public space. The main difficulty was the automatic generation of SEO texts based on templates since manual content development for 100K+ pages was not possible.
We had to create landing pages for categories like "sneakers" and "dresses," properties like "leather" and "embroidered," and the general characteristics "female," "male," and "for children. Such pages would be titled "children's red sneakers" or "evening dresses with embroidery.
Example of template:
{name_plural_nominative} from {min_price} to {max_price} UAH Favorable prices for the purchase{product_count}{name_plural_genitive} in {store_count}online stores
Examples of generated texts:
Dress from 500 to 50 000 UAH. Attractive prices for the purchase of 12 544 dresses in 105 online stores
Sneakers from 2500 to 20 000 UAH. Attractive prices for 1 244 sneakers in 105 online stores
Necklaces from 200 to 200 000 UAH. Attractive prices for the purchase of 4 025 necklaces in 44 online stores
The special difficulty was that we developed the product for the Baltic-Slavic branch of languages, where adjectives have different forms depending on noun's grammatical gender. Also, it was important to follow the correct word order during content generation. Some characteristics had to occur before the noun, like "red sneakers," and some after, like “sneakers with high heels". To solve the mass generation of such pages, content managers had to specify all the necessary word forms of product properties and categories. The algorithm chose the proper word form for the grammatically correct construction of the parts of SEO texts for successful page promotion.
After agreement on business requirements, we start to work. We decided to split the development on several stages to have an opportunity to check the quality achievement of goals upon completion of each of them:
The solution had to process thousands of XML feeds every day, and each file could contain up to a million products. We decided that the solution should correctly process up to 5M products. Also, our module should receive and parse product pages on the store's website daily for each product in XML feeds. Then we stored all the structured data in the database.
The solution of collecting data from webpages was the strong feature. XML feeds didn't always contain complete and up-to-date information, whereas pages on websites were supposed to be relevant. That's why all the necessary data was there. The best example of an important data is the item's price on the site. We had accurate information about product price history by constantly collecting prices from web pages, which allowed us to calculate accurate price discounts based on actual price history.
It had to contain interfaces for managing data sources, the tree of categories, filters, blog pages, and other entities. The content manager should be able to add a new store; set rules for parsing XML files and HTML code of pages. Also, they can specify rules to determine whether a product falls into a particular category or filter. In addition, we needed features for managing the SEO content of pages: manual editing of data for specific pages and mass generation of content by a set of templates.
This module received the data collected by xml-parser from the database and determined for each product its categories and filters, according to the settings that content managers defined on the admin admin. After that core saves the data in the database in an appropriate form for the web application.
Technically task was like this. We have about 10^7 of texts — data from product fields. For each text, we need to define all occurrences of strings from normalization rules as substrings or prefixes. There were about 10^6 of such strings. The best algorithm to solve this problem was an Aho–Corasick algorithm — the classic algorithm for searching the set of substring from the dictionary in a given string. On the biggest real data set in the Pre-Seed stage, this algorithm solved tasks with less than two hours, with a planned limit of 12 hours.
It had to contain pages of categories and filters, pages of goods, and blog publications. As search engine optimization was one of the most critical tasks, we reached a high page load speed — 99% of pages were loaded at no more than 200 ms.
Everything passed smoothly — we solved all technical difficulties and successfully released the product. By the end of 2016, active development was stopped because the product had all the essential things for testing a business model.
With this product, the client took part in many conferences and held pitches for many investors. At the same time, the product keep continued to generate income and validate its business model.