Процес
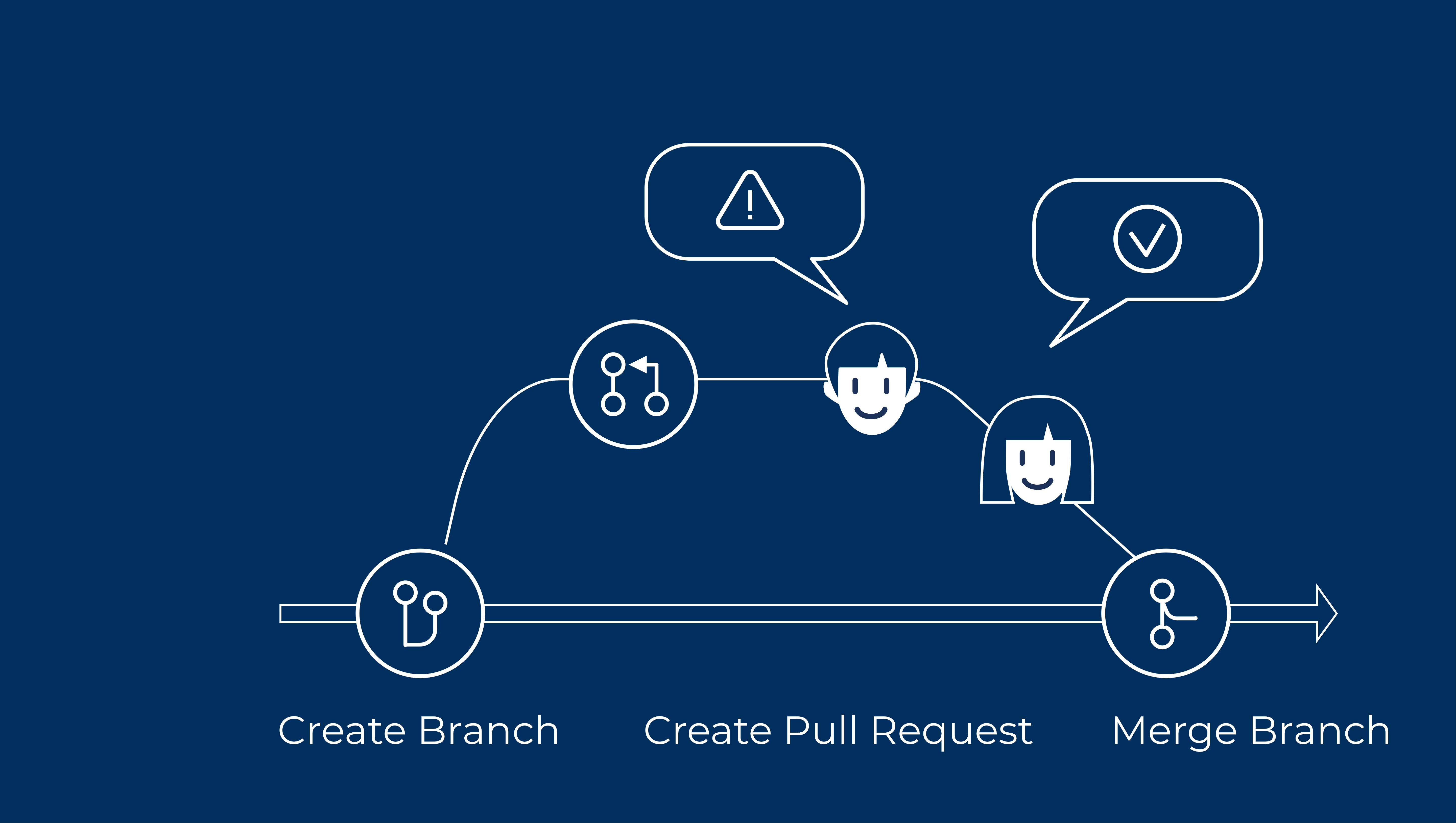
Технічний аналіз і системне тестування
[ Пишіть код так, немов би підтримувати його буде схильний до насильства психопат, який знає, де ви живете ]
— Джон Вудс. Ми проти насильства але згодні з підходом
Тестування і контроль архітектури для продуктів ранніх стадій значно відрізняється від того, як це працює на зрілих продуктах. Гіпотез дуже багато, розуміння ринку підприємцем змінюється часто, вимоги змінюються непередбачувано. При цьому фундаментальні функції продукту мають залишатися у безпеці – вони мають працювати добре і бути готовими до зростання обмежень.
Ми не можемо дурити себе, що маємо чіткий і реалістичний roadmap на півроку уперед, ми зобов'язані враховувати мінливість об'єктивних задач продукту. Наприклад, якщо план розвитку продукту на 2-3 місяці уперед з великою ймовірністю не зміниться, то окремий процес тестування, що виконується QA Lead й тестувальниками є повністю обґрунтованим. Але в більшості наших кейсів є більш рентабельним, якщо розробники самі тестують продукт, бо вони знають і розуміють сьогоднішній стан вимог. Саме вони мають умови, щоби якісно перевірити продукт на відповідність цим вимогам.
Ми аналізуємо правильність і передбачуваність усіх аспектів інкременту, розглядаємо крайні випадки і некоректні вхідні дані. Ми переконуємося, що при отриманні будь-яких некоректних даних система залишається працездатною. Якщо вимоги містять ліміти, в які рішення має вписуватися, то ми переконуємося у тому, що ця частина задачі виконана. Ми закладаємо можливості для збільшення обмежень на порядок чи більше, коли у цьому є мінімальна потреба. Для кожної частини продукту ми маємо чітке бачення, в який спосіб можна підвищити обмеження та як це відіб'ється на стабільності продукту.
Код-база будь-якого продукту – це його суть у плоті. Підтримуваність код-бази є вкрай важливою, тому кожен інкремент рано чи пізно оцінюється іншим розробником. Ми розглядаємо код-базу під кутом різних сценаріїв взаємодії з нею – планування інкременту, розробка вже запланованих інкрементів, пошук багів. В залежності від нашої оцінки, що рішення конкретної задачі буде потрібне в продукті на довший час, ми визначаємо скільки енергії і часу варто витратити на аналіз його технічної якості. Але якщо кожний день затримки випуску функції призводить до суттєвих втрат прибутку нашого клієнта, ми точно не будемо сперечатися, який дизайн класу Х є кращим. Завдяки такому підходу наші code review є гнучкими, не блокуючими і результативними.
Ми прагнемо підтримувати наш процес розробки і технічної дискусії максимально продуктивними. Тому ми використовуємо статичні аналізатори editorconfig і інші інструменти цього спрямування. Завдяки такому інструментарію ми маємо єдину систему прийняття рішень по стилістичним питанням і ми можемо сфокусуватися на головному.
Для зрілих модулів і застосунків ми розробляємо і супроводжуємо автотести. Завдяки їм ми створюємо якісну документацію на продукті й знижуємо загрози людського фактору. Автоматичний тест – це не просто інструмент для виконання обмежень на підсистемі. В той самий час тест є точним фактом, записаним розробником: результат роботи коду має бути точно таким. Крім того, трапляються випадки, коли розробити якийсь модуль є швидше, попередньо написавши до нього тести. Ці тести також є цінним інкрементом у код-базу. Крім вже озвучених переваг, вони ще показують хід думки розробника та його розуміння задачі, що є дуже цінним для release manager та майбутніх членів команди. На нестабільних підсистемах вимоги застарівають дуже швидко. Тому на MVP і тимчасових рішеннях ми нерідко відмовляємось від автоматичних тестів на користь швидкості розробки.
Ми використовуємо усі ці підходи та техніки, щоби зберігати технічну якість наших продуктів високою, а ціни на наші послуги – оптимальними.

Перевірка якості на рівні продукту
Наші клієнти цінують нас за високі внутрішні стандарти. Мова йде не стільки про чистоту коду, формальне виконання узгоджених вимог чи стовідсоткове покриття юніт-тестами. Причина, через яку з нами працюють – ми робимо максимум з того, що можемо, в інтересах кінцевого споживача продукту і на користь нашому клієнту.
Перейдімо до конкретики й розглянемо блок задач. Перед релізом треба переконатися, що він дійсно добре вирішує бізнес-задачі, для яких він був створений. При сборі вхідних даних ми домовились з клієнтом про конкретні бізнес-цілі і чітко зафіксували їх. Під час розробки вимог ми описали чіткий критерій приймання блоку задач. В рамках системного тестування ми переконались, що інкремент є стабільним і не загрожує системі. Робота майже готова, і треба тільки успішно провести реліз на production. Чи не так? Спробуймо розібратися.
Насамперед ми переконуємося в актуальності всіх вхідних, що стосуються блоку задач, що перевіряється. Ми це робимо наступним чином:
- Відповідальність клієнта – тримати нас в курсі змін процесів на його боці, щоби ми завжди працювали з актуальними вхідними. Іноді клієнту неочевидно, що якісь зміни в процесах його компанії впливають на наш продукт. Ми ставимо за мету звертати увагу клієнта на такі моменти і з'ясовувати їх.
- Після того як ранні стадії продукту пройдені, ми маємо набір базових продуктових метрик, за якими системно спостерігаємо. Якщо ми бачимо якусь аномалію, то це є приводом уточнити з клієнтом, чи не змінилось щось на його боці. Процес обробки баг-репортів також є ефективним для актуалізації розуміння процесів навколо продукту. Якщо ми бачимо суперечності в якомусь user flow, ми, при необхідності, обговоримо це питання з клієнтом і переконаємося, що бачимо поточні задачі і цілі однаково.
- Переконавшись в актуальності плану перевірки якості інкременту, ми переходимо до його впровадження. На цьому рівні ми працюємо з цілями користувача, його очікуваннями і поведінкою. При першому контакті з продуктом користувач може не вповні розуміти свою задачу. Тому інтерфейс має підказувати користувачу як можна використовувати продукт. Користувачі можуть бути різними за своїм професійним і культурним рівнем, можуть мати рівний рівень технічної грамотності. Тому інтерфейси мають бути адаптовані для цільової аудиторії, і це варто перевіряти на практиці. Нарешті, користувач може здійснювати непередбачувані і навіть шкідливі дії. У цей час продукт має ефективно підказувати йому правильний сценарій взаємодії та застерігати від некоректних дій.
Після того як ми переконалися, що з інкрементом у продукт все гаразд на поточний момент, ми оцінюємо його готовність до майбутніх загроз. Зростання продуктових ризиків ми оцінюємо виходячи з фінансових інтересів наших клієнтів. Підготувавши якісну оцінку ризиків, ми надаємо її клієнту і спільно вирішуємо – ми приймаємо ризики чи змінюємо наш план дій.
Рівень досягнення цілей продукту можна й треба обчислювати, без цього будь-яка оцінка якості продукту буде суб'єктивною. Але щоби отримані метрики були робочими, мають бути дотримані умови.
- Для будь-якої метрики потрібна репрезентативна вибірка користувачів, на якій метрика має сенс. Найпростіший приклад: немає сенсу оцінювати рівень конверсії посадкової сторінки, доки немає можливості залучити на неї аудиторію, зацікавлену у продукті.
- Метрики мають бути прикладними, себто мають бути визначені правила їх тлумачення. Припустимо, на тій самій посадковій сторінці 40% користувачів гортають до третього екрану. Далі що? Як цей факт може збільшити продажі?
- При програмному зборі даних для метрики технічна реалізація має бути досить якісною. Уявіть ситуацію, коли закуповується трафік на посадкову сторінку, а розробник реалізував інтеграцію з Google Analytics так, що вона не працює на мобільних телефонах; в результаті, бюджет був би витрачений марно.
Ми не припускаємось подібних помилок. Деякі продуктові метрики можна збирати програмно, і ми робимо це за допомогою 3rd-party (по типу Google Analytics или AppsFlyer), аб ж за допомогою кастомних розробок. В деяких випадках це дуже трудомістко, і значення метрик вигідніше визначати вручну у потрібні моменти часу. Ми завжди оберемо оптимальний спосіб для найбільш доцільного збирання метрик. Найважливішим є, що нашим продуктовим метрикам можна довіряти.
Ми добре розуміємо, наскільки складно зробити якісним не просто код, а саме продукт. Якщо ми вступаємо у співробітництво, ми приймаємо відповідальність за рівень продукту, який ви отримаєте в результаті. Ця робота – суть нашої компанії, і ми справляємося з нею професійно.

Проведення релізу
Ми пишаємось частотою і непомітністю наших релізів. Це справедливо і для маленького quickfix, і для мажорного релізу продукту. Коли ефект інкременту є зрозумілим клієнту і добре оцінений нашою командою, ми майже завжди можемо випустити його швидко і безболісно. Тільки в тих випадках, коли проведення релізу може створити загрози стабільності продукту, ми попереджаємо про це клієнта і блокуємо на час релізу функціональності, що можуть загрожувати.
Безумовно, при будь-якому релізі найважливіше – не нашкодити поточному стану системи. Тому при кожному релізі ми маємо план того, як швидко повернути продукт до попереднього стану без втрат. У складних випадках ми перевіряємо цей план у безпечному оточенні, еквівалентному production. Але, як правило, типовий процес покриває переважну більшість сценаріїв проведення релізу.
Процес проведення релізу, зазвичай не потребує багато часу. Ми завжди розробляємо сценарій деплою на самому початку проєкту, ще до першої демонстрації клієнту чи тестовій групі користувачів. Він дає нам змогу випустити змінену версію застосунку на середовище натисканням однієї кнопки. Для користувачів наші релізи майже завжди відбуваються непомітно. У випадку релізу веб-застосунків максимум, що може помітити користувач – враження, що на пару секунд впав інтернет. А якщо саме у цей час якісь користувачі очікували відповідь від сервера щодо успішності проведеної ними оплати послуг продукту? Немає проблем, ми відпрацьовуємо такі ситуації дуже уважно, і поведінка сервісу буде точно такою, як ми планували.
Але іноді задача буває більш складною чи заплутаною. Наприклад, ми додаємо нові ресурсомісткі функціональності, на кшталт складного пошуку з великою кількістю параметрів по великій базі об'єктів. Для такого випадку може знадобитися змінити структуру зберігання даних, побудувати індекси в базах даних тощо. Такі речі потребують часу. Поки наші скрипти деплою провадять зміни, можливість взаємодіяти з даними може бути заблокована для користувачів. Саме у таких випадках може бути доречним нестандартне рішення. Ми оцінимо ризики системи, врахуємо інтереси нашого клієнта і кінцевих користувачів і після цього оберемо оптимальне рішення. У випадку, якщо короткострокове відключення системи буде оптимальним рішенням, ми своєчасно повідомимо користувачів про проведення технічних робіт. Якщо такий варіант є неприпустимим, ми маємо немало хитромудрих способів як влаштувати непомітний реліз і в таких умовах.
Закон Лінуса – це емпіричне спостереження, яке стверджує, що при достатній кількості спостерігачів помилки спливають на поверхню. У нашій практиці це спостереження особливо часто підтверджується при проведенні релізів. Тому на наших продуктах релізи зазвичай проводяться як мінімум двома співробітниками. У випадку форс-мажорів ми маємо набагато вищі шанси швидко знайти і усунути проблему.
Після успішного проведення релізу ми обов'язково перевіряємо стан системи – чи не сталося погіршень. Значну частину цих робіт ми автоматизували. Автоматичні тести гарантують, що покриті ними функціонали працюють коректно. Завдяки утилітам моніторингу життєвих і продуктових показників ми знаємо, що наша інфраструктура і продукт є в порядку. За допомогою Sentry ми контролюємо технічні виключення в нашій код-базі. Аби бути переконаними у безпомилковості нового стану продукту, ми так само перевіряємо статус і вручну. Після того, як ми переконуємося в точності нашої оцінки результатів релізу, ми обов'язково документуємо ці результати. Мінімальна форма цієї документації – достатньо докладні release notes.
Випуск нової версії продукту – завжди приємний момент. Кожний успішний реліз зміцнює нашу взаємну довіру з клієнтом і допомагає рухатись уперед. Нас мотивує вдячність наших клієнтів, які тепер користуються більш ефективним продуктом.
Збір і аналіз зворотного зв'язку
Як зрозуміти, що ми робимо все правильно? Зворотний зв'язок – єдиний спосіб узнати це напевно. Зібравши зворотний зв'язок, ми зіставляємо цілі розробки з реальним результатом. Ґрунтуючись на аналізі зворотного зв'язку ми оцінюємо готовність продукту до загроз росту і розвитку. А саме: продуктові загрози оцінені адекватно, розробляти і оцінювати нові функції не стало складніше, і власники продукту бачать процес успішним.
Найпростіший спосіб збирання зворотного зв'язку – face-to-face. Для цього ми залучаємо кінцевих користувачів продукту. Ми створюємо умови, щоби зворотний зв'язок був достовірним. Пропонуємо agenda зустрічі заздалегідь, щоби респондент мав достатньо часу на підготовку. У процесі взяття зворотнього зв'язку ми документуємо його з потрібним ступенем деталізації на місці.
Не варто забувати, що спосіб зворотного зв'язку face-to-face – це тільки верхівка айсбергу. Як би респонденти не були мотивовані у наданні зворотнього зв'язку, повну картину таким чином сформувати не вдасться. З наступних причин:
- Рівень компетентності респондента може бути недостатнім для достовірної відповіді на питання. Наприклад, користувач CRM-системи не дасть конструктивну оцінку ефективності інтерфейсу. Він може навіть не уявляти, що його можна зробити кращим.
- Зворотний зв'язок іноді викривляється під впливом суб'єктивних факторів настільки, що його не можна вважати достовірним. Якщо ми чуємо від респондента щось на кшталт «м-м-м, здається, все нормально», цьому «нормально» вірити не варто.
- Вибірка респондентів зазвичай є перекошеною.
Існують і інші способи зворотного зв'язку. Респонденти дають його своїми діями, навіть не усвідомлюючи, що ці дії і є зворотний зв'язок. Наприклад:
- Кількісні метрики використання продукту в production. Якщо функціональність використовується рідше очікуваного – це вірна ознака, що там щось не так. Якщо середній час взаємодії з інтерфейсом перевищує очікування – напевно щось залишилось не врахованим.
- Непередбачені технічні помилки при використанні функціонала. Ми відстежуємо їх за допомогою Sentry, іноді – за допомогою моніторингу на базі Prometheus з оповіщеннями, іноді за допомогою ELK. Ми аналізуємо ці помилки і визначаємо чи призводять вони до проблем.
- Запити користувачів про виправлення проблем. Якщо новим функціоналом користуються і на нього нема скарг, то, найімовірніше, він реалізований непогано. За кількістю реальних помилок і за результатами їх виправлень можна зробити достовірний висновок щодо чистоти релізу.
Відповідно, ретроспективний аналіз відбувається в процесі збирання зворотного зв'язку. Ми оцінюємо кожну потенційну проблему за шкодою, яку вона може принести нашому клієнту. Про всі наші підозри щодо проблем ми без затримок повідомляємо клієнтів, надаючи повний контекст ситуації й усі необхідні подробиці.
Якщо клієнт повідомляє про суттєву проблему, ми вивчаємо її вкрай швидко і досконало, тому що найважливіше для роботи продукту її усунути. Розв'язавши проблему, ми аналізуємо ситуацію, документуємо помилки, що трапились і знаходимо способи відвернути їх в майбутньому.
Ми не боїмося критики у зворотному зв'язку, ми високо її цінуємо. Диму без вогню не буває, тому ми завжди відкриті для обговорення навіть гіпотетичних проблем. Ми проактивні, бо простіше помітити проблему на початках і усунути її, захистившись від її наслідків. Зворотний зв'язок робить нас більш професійними, тому ми вміємо працювати з ним. Навіть якщо це дуже непросто.
Кожний елемент ілюстрації процесів розробки — це посилання на статтю. Натисніть на неї, щоб дізнатися більше.
