Рішення
AllPrices
Price aggregator
- Тип послуги:
- Agile development
- Тип продукту:
- Price aggregator
Рішення

E-commerce — це величезна ніша IT-продуктів, що з'явилася однією з перших, через що конкуренція серед продуктів цього домену достатньо висока. В цьому кейсі ми не тільки побудували великий продукт в цій ніші і вирішили його найскладнішу технічну задачу, але дізналися складності розвитку продукту на висококонкурентному ринку. Продуктом в цьому співробітництві був прайс-агрегатор, працюючий з інтернет-магазинами за моделлю CPA. AllPrices регулярно збирав товари більшості онлайн-магазинів і видавав їх за пошуковими запитами користувачів. Ми змогли побудувати продукт, що аналізував велику кількість товарів і допомагав своїм користувачам знаходити найкращі пропозиції.

В процесі пошуку нашим клієнтом ефективної бізнес-моделі ми провели декілька суттєвих півотів продукту, зберігши його ефективність. Ми вирішували для нашого клієнта всі задачі розробки на двох великих стадіях продукту: під час Pre-Seed стадії, при запуску продукту на ніші fashion, і на Seed стадії, коли продукт мав би покривати всі товарні категорії. В результаті Pre-Seed ми побудували продукт, який успішно отримав посівну інвестицію. За рахунок цих грошей, продукт вступив у суперництво з компаніями, які в сотні разів більше нашого клієнта з капіталізації. Наш клієнт всеохоплююче вивчив нішу, а ми успішно вирішили всі технологічні задачі в процесі перевірки бізнес-моделі. Почавши свою роботу у 2016 році, продукт був офіційно закритий в 2021, тоді наш клієнт надав нам виняткові права на публікацію всіх подробиць процесу роботи. Через це, кейс містить багато деталей, які рідко висвітлюють у публічному просторі.
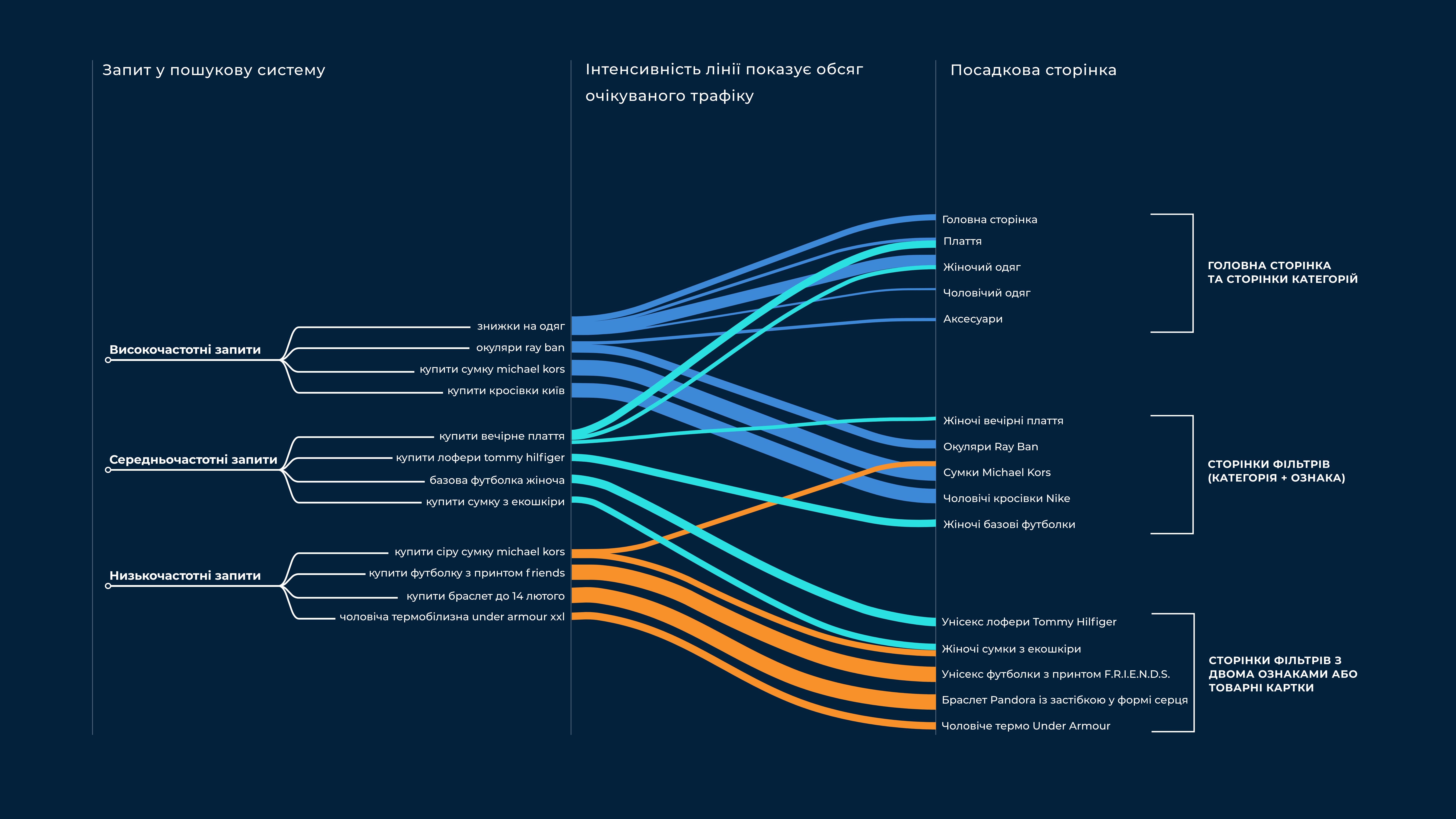
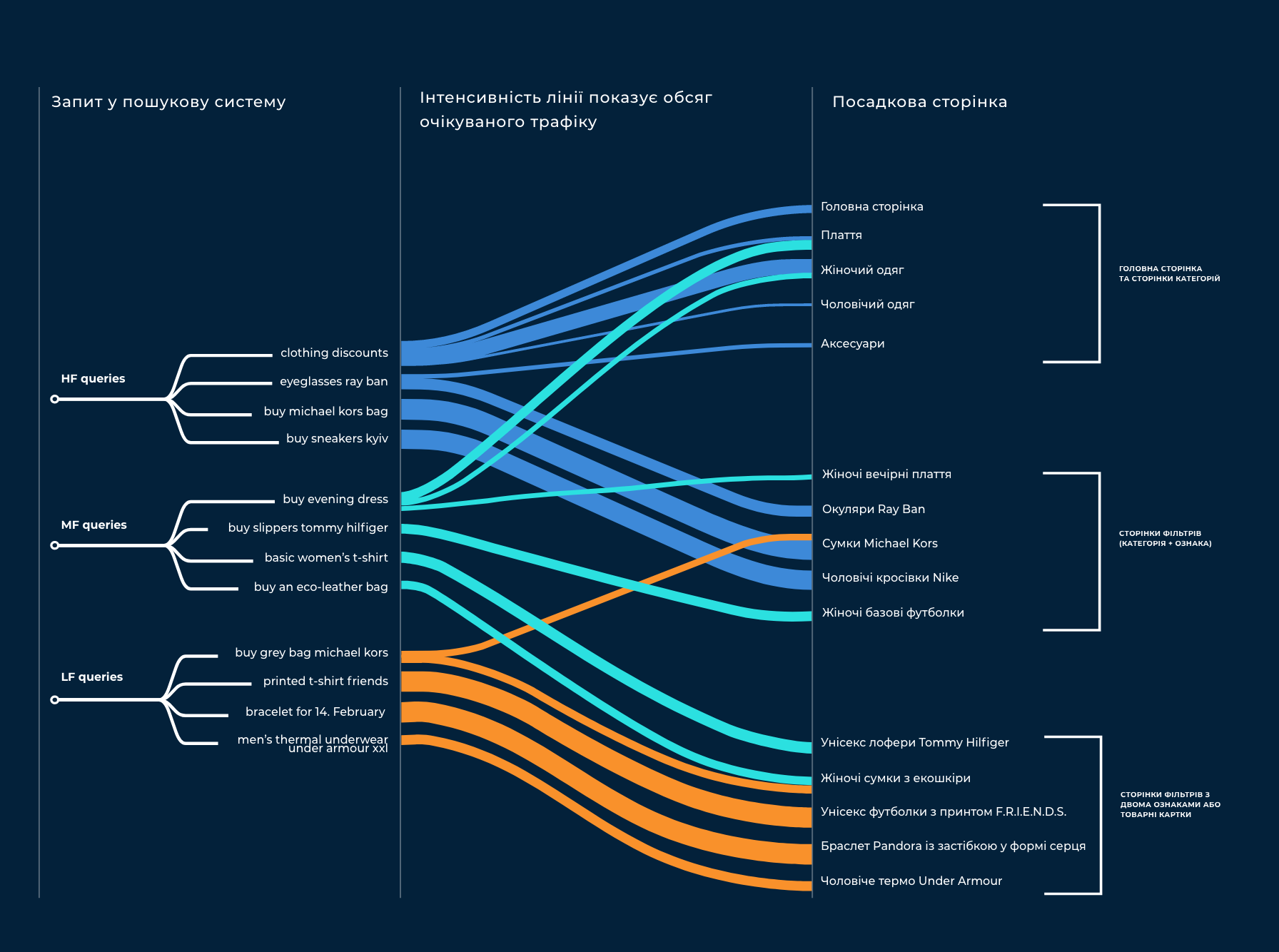
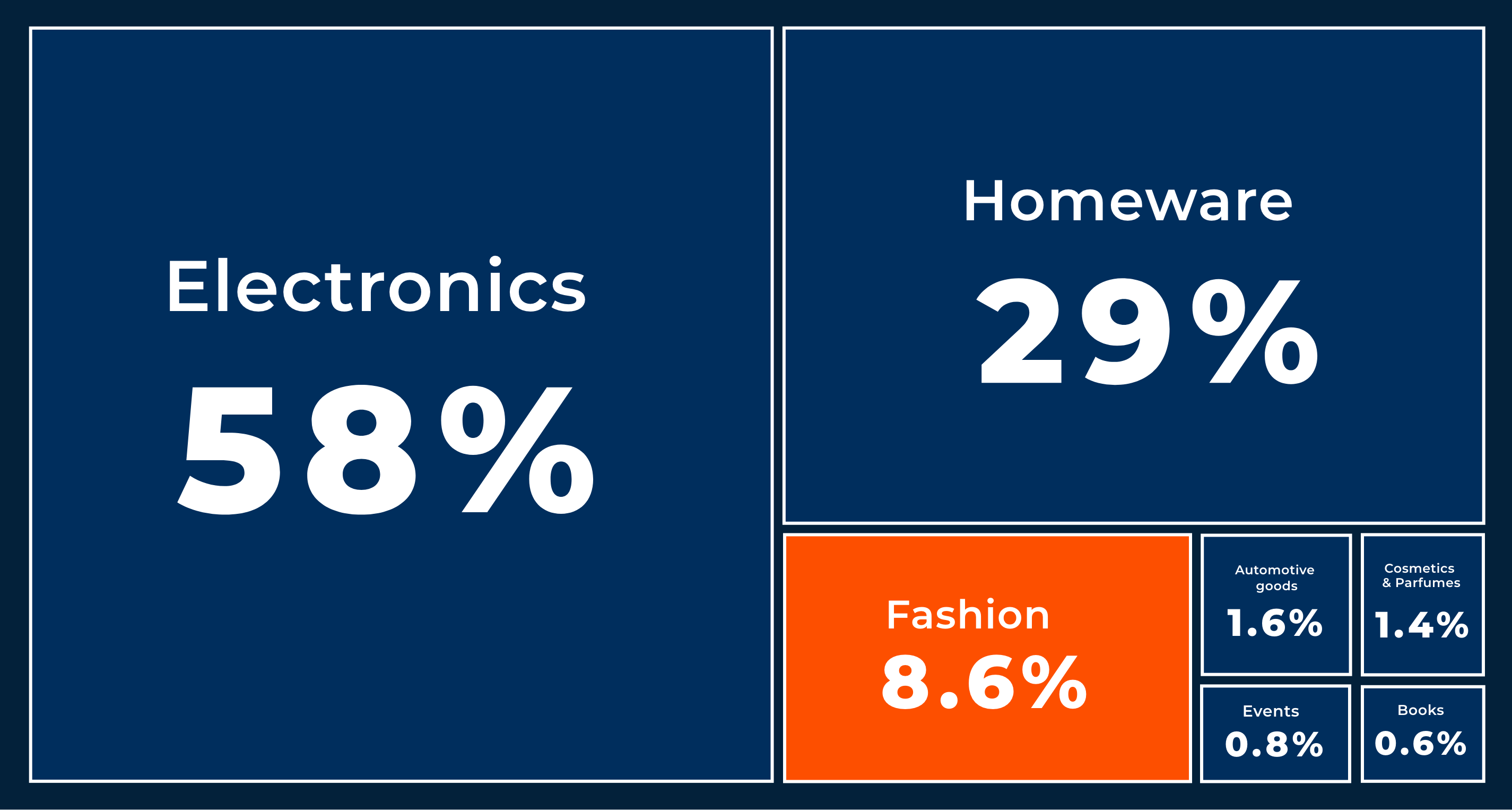
У 2016 році e-commerce ринок у ніші fashion у Східній Європі був диференційованим — було багато продавців різного масштабу, але продавали достатньо різні речі. Ідея першої версії AllPrices була простою — потрібно зібрати всі товари ніші fashion на одному сайтів побудувати зручну для користувача структуру категорій і фільтрів, вивести справжні знижки на всі товари. Основним каналом трафіку на цій стадії був органічний, при тому від самого початку суттєва роль приділялась низькочастотним запитам. Наш клієнт побачив можливість масово підготувати для таких запитів сторінки з релевантними товарами і таким чином отримати суттєвий трафік.
Низькочастотні запити — це такі, що отримують мало трафіку, до 1000 або навіть до 100 заходів на місяць. Багато сайтів не приділяють суттєвої уваги просуванню за такими запитами, так як якісна проробка сторінок під них часто виявляється занадто затратною.
Тоді ми вирішили, що у ніші fashion при великій кількості товарів такий задум міг відмінно спрацювати. Люди часто можуть шукати за точним запитом — наприклад, що містить бренд кросівок, колір шарфа або текст принт на футболці. Також, вони побачать на першій сторінці пошуку, не завжди релевантні запиту, сторінки окремих магазинів, які не містять всіх потрібних товарів. Через це, наша майбутня сторінка з товарами усіх магазинів саме за цим запитом виглядала для нас відмінним варіантом для відвідувача — саме вона могла з високою вірогідністю привести користувачів до бажаної покупки.
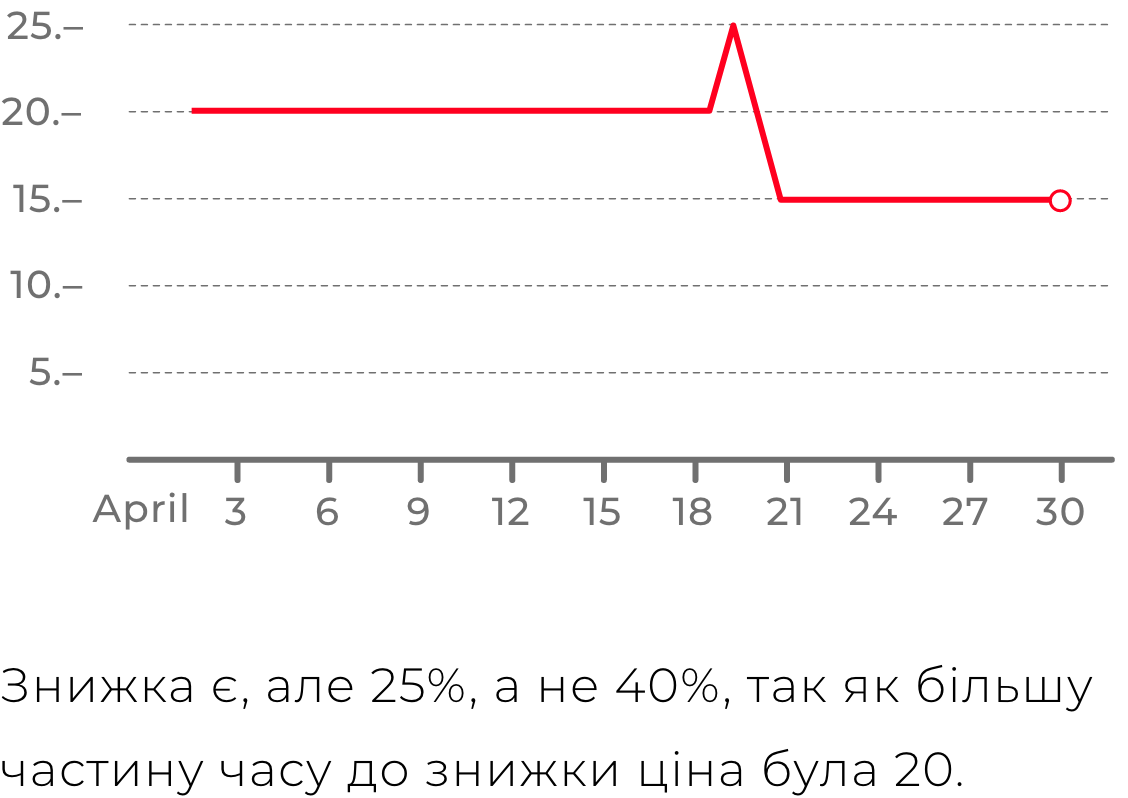
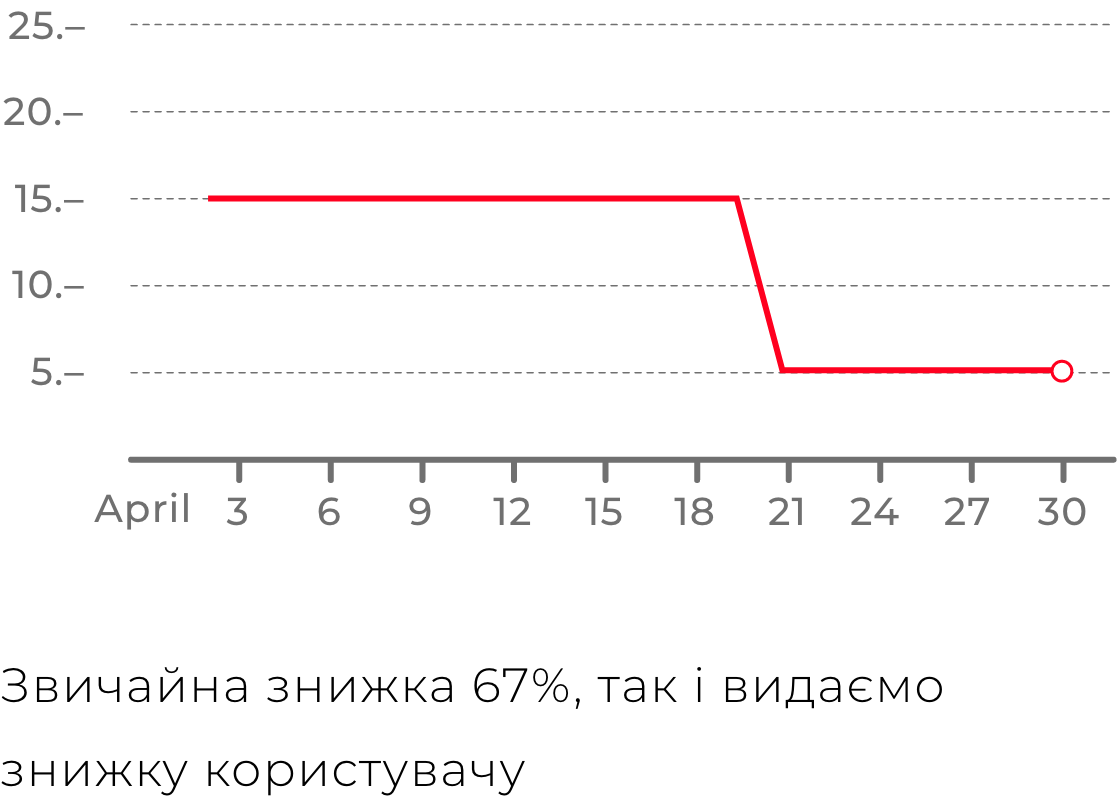
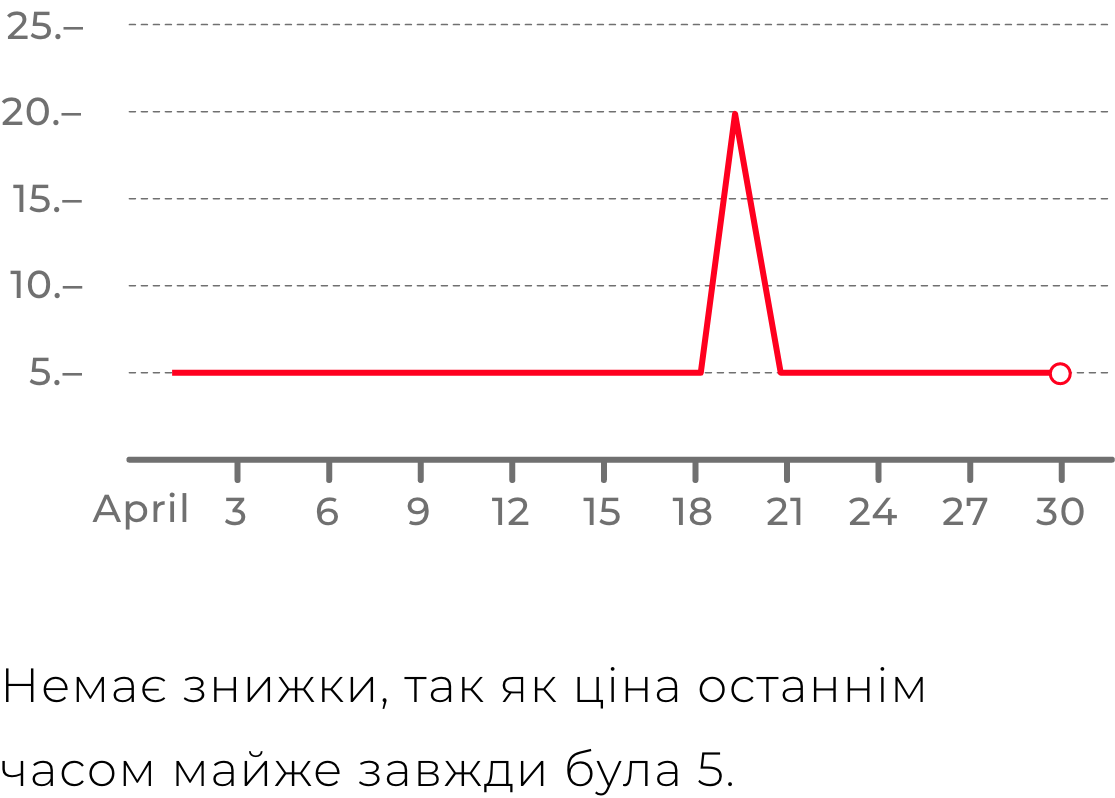
Крім зручності пошуку серед усіх магазинів всередині ніші, продукт мав би запропонувати користувачеві чесні знижки. Якщо продукт відстежував ціни товарів кожного дня, то він може правдиво оцінити наскільки теперішня ціна відрізняється від звичайної. І ця оцінка буде справжньою, у відмінності від багатьох магазинів, які могли просто повісити на товар бейджик “знижка”, коли за попередні 30 днів ціна на цей товар була такою ж самою.

Цілі, які ми тоді сформулювали з нашим клієнтом, були більш технологічними, ніж продуктовими. Головною на цьому етапі була задача довести, що такий продукт можливо побудувати в умовах Pre-Seed інвестиції. Цілі ми визначили так:
Для нашого клієнту стек розробки був принциповим питанням. Наш клієнт мав досвід розробки продуктів з роботи в Cuponation (один з суттєвих гравців цього ринку), де він щільно взаємодіяв з розробниками. Спеціалісти, що його проконсультували, порекомендували такий стек:
Yii2 – популярний у східній Європі PHP-фреймворк для web розробки в той час.
PostgreSQL – один з двох найпопулярніших open-source РСУБД.
Memcached – бібліотека PHP для кешування даних сторінок.
Redis – для кешування даних проміжних прорахувань.
Ми вивчили задачу глибоко і побачили деякі продуктові ризики, тому запропонували більш відповідний стек. Yii2 був відповідним рішенням для нас, так як тоді цей фреймворк був найбільш відповідним для agile розробки з відомих нам. PostgreSQL для стартапів. Memcached та Redis ми не бачили фундаментально важливими технологіями продукту, хоча й припускали їхнє використання за необхідністю.
В рішенні прорахування даних про потрапляння товарів в категорії і фільтри ми помітили суттєву обчислювальну складність. Тому ми запропонували зробити особливі рішення на С++, приймаюче на вхід зібрані дані з джерел, і що провантажує дані про категорії та характеристики прямо в БД. Також, ми врахували, що нам потрібно буде збирати дані з більш 1М сторінок товарів, щоб збагатити набір даних. Для такого рішення ми запропонували фонову рутину, реалізовану на Python для стабільного збору цих даних і їхнього імпорту в нашу БД. Наші пропозиції були повністю прийняті клієнтом.
Складною задачею була розробка процесу визначення характеристик товарів. Ми поцілили у визначення 100К+ характеристик по 1М+ товарів, тому про ручну проробку не могло бути й мови. Ми вирішили розробити принцип, за яким система могла б чітко виявити чи має товар кожну з характеристик. В якості вхідних даних ми мали сирі дані про товари з XML-дампів і дані з парсингу HTML-сторінок. Спрощуючи, це були поля “Описання”, “Матеріал” чи “Розмір”, значенням яких були рядки чи числа. Ми розробили примітивну мову виразів, кожні з яких виявляло критерій, чи має товар якусь з характеристик. Ми назвали такі вирази правилами нормалізації. Вони мали приблизно такий вигляд:
((Назва містить префікс “плат”) або (Опис містить префікс “плаття”)) та
НЕ ((Назва містить префікс “пляжн”) або (Опис містить префікс “пляжн”))
Іноді сарафани називають "пляжними платтями". Вони повинні потрапляти в категорію "сарафани", тому якщо назва містить префікс плаття та префікс пляжний — це сарафан, а не плаття. Такі вислови ми змогли згенерувати автоматично за більшістю характеристик. За всіма категоріями і за найбільш популярними характеристиками ці вислови опрацював вручну контент-відділ нашого клієнта.
Наступною продуктовою задачею було зробити можливість управляти всією структурою сторінок платформи на панелі адміністратора. Дерево категорій було достатньо типовою в цій ніші задач. В той самий час створення якісних сторінок фільтрів виглядало задачею, про яку немає жодної інформації в публічному просторі. Головною складністю була автоматична генерація SEO-текстів за шаблонами, тому що ручна проробка контенту за 100К+ сторінкам не була можливою.
Нам потрібно було створювати можливості за категоріями типу “кросівки” та “сукні”, властивостям типу “шкіряні” і “з вишивкою” і загальним характеристикам “жіночий”, “чоловічий” і “для дітей”, створювати повноцінні посадкові сторінки. Які мали б назву “дитячі червоні кросівки” або “вечірні сукні з вишивкою”.
Приклад шаблону:
{name_plural_nominative} від {min_price} до {max_price} грн Вигідні ціни на покупку{product_count}{name_plural_genitive} з {store_count}інтернет-магазинів
Приклади згенерованих текстів:
Плаття від 500 до 50 000 грн. Привабливі ціни на покупку 12 544 суконь з 105 інтернет-магазинів
Крокси від 2500 до 20 000 грн. Привабливі ціни на 1 244 кроксів з 105 інтернет-магазинів
Намиста від 200 до 200 000 грн. Привабливі ціни на покупку 4 025 намиста з 44 інтернет-магазинів
Особливою складністю було те, що ми розробляли продукт для балтійсько-слов'янскої гілки мов, в якій закінчення прикметників, як правило, сильно залежали від іменника, до яких вони відносились. Крім того, при генерації потрібно було враховувати порядок слів — деякі характеристики потрібно було вказувати до іменника як “червоні кросівки”, а деякі — після, як “кросівки New Balance”. Для вирішення масової генерації таких сторінок ми визначили набори полів для кожної сутності, в яких контент-менеджери повинні були вказати всі необхідні відміни потрібних слів. Алгоритм використовував потрібні з них для граматично коректного побудування частин SEO-текстів, необхідних для успішного просування сторінок.
Обумовивши бізнес-вимоги, ми перейшли до роботи. Розробку ми вирішили розбити на декілька етапів, щоб мати можливість перевірити якість досягнення цілей після завершення кожного з них:
Рішення повинно обробляти тисячі XML-фідів з товарами магазинів щодня, кожен файл міг містити до мільйону товарів. Ми вирішили, що продукт має коректно обробляти до 5М товарів всього. Для кожного товару модуль збору даних повинен як мінімум щодня отримувати вміст сторінки товару на сайті магазину і парсити дані звідти в нашу структуру даних. Всі структуровані дані ми зберігали в БД.
Саме рішення збору даних зі сторінок стало сильною функцією продукту. XML-фіди не завжди мали повну і актуальну інформацію, тоді як сторінки на сайтах мали бути продаючими. Тому там були всі необхідні дані. Кращий приклад важливого даного — ціна товару на сайті. Саме за рахунок безперервного збору цін зі сторінок сайтів ми володіли достовірною інформацією про історію цін на товари, що дозволило нам прораховувати правдиві знижки, побудовані на реальній історії цін.
Вона повинна містити інтерфейси управління набором джерел даних, деревом категорій, набором фільтрів, сторінками блогу та іншими сутностями. Контент-менеджер повинен мати можливість самостійно додавати новий магазин для отримання товарів з нього, задати правила розбору XML-файлу і HTML-коду сторінок. Також він може налаштувати спосіб визначення чи попаде товар в ту чи іншу категорію або фільтр. Крім цього були потрібні функції керування SEO-контентом сторінок: ручне редагування даних однієї сторінки і масова генерація контенту за набором шаблонів.
Цей модуль отримував дані, зібрані xml-parser з БД, визначав для кожного товару його категорії і фільтри за налаштуваннями, які контент-менеджери визначали на admin. Після цього core відправляв дані у БД вже у зручному вигляді для видачі даних користувачеві.
Технічно задача була такою. У нас є близько 10^7 текстів — дані полів товарів. Для кожного тексту потрібно визначити всі входження рядків з правил нормалізації як підрядків або префіксів. Таких рядків було близько 10^6. Кращим алгоритмом для рішення такої задачі був бор Ахо-Корасик — класичний алгоритм пошуку багатьох підрядків із словника в даному рядку. На найбільшому реальному наборі даних в рамках Pre-Seed стадії цей алгоритм вирішував задачу за менш ніж дві години роботи, при плановому обмеженні в 12 годин.
Сам сайт мав складатися зі сторінок категорій і фільтрів, сторінок товарів, публікацій блогу. Так як задача пошукової оптимізації була однією з головних, ми здобули високу швидкість видачі сторінок — 99% сторінок видавалися не більше ніж за 200 мс.
Все пройшло гладко — ми змогли вирішити всі технічні складності і успішно випустити продукт. До кінця 2016 року активна розробка припинилася, так як продукт володів усім необхідним для тестування бізнес-моделі.
З цим продуктом клієнтом прийняв участь у багатьох конференціях і провів пітчі багатьом інвесторам. У цей самий час продукт продовжував генерувати прибуток і підтверджувати свою бізнес-модель.